
In the world today, the internet still uses many of the protocols from when it was first developed in the 1970s and ‘80s. As more people and devices are connected than ever before, and while the demands of global internet systems grow larger and more complex, the internet’s current underlying architecture is still mostly antiquated.
The weakness of this aged technological architecture has become critical. Attacks such as distributed-denial of service (DDoS) are now both commonplace and difficult to handle. Similar attacks have even temporarily knocked websites like Amazon, Twitter, and Reddit offline.
A method called deep packet inspection (DPI) is prevalent and reveals the full content of data packets as they traverse the global interwebs. While DPI can be used for benevolent purposes, such as preventing attacks, it also represents a general loss of privacy and gives state organizations enormous power over end-users.
Data breaches have become extremely common such that nearly every day there is a news story about another incident occurring. The victims of these data breaches are both civilians, organizations, and governments. It’s clear that privacy and more efficient routing protocols are urgently required.
Cjdns is a mesh routing protocol that was introduced by cryptographer, security analyst and mesh networking expert Caleb James DeLisle in 2011. Cjdns uses public-key cryptography for address allocation and a distributed hash table for routing. The protocol is designed to address some of the internet’s most pressing issues, such as data privacy, need for decentralization and optimized, efficient routing. The core premise of the cjdns technology is both solving these problems, as well as making network infrastructure operation a possibility for tech savvy operators, instead of just monopoly internet service providers (ISP) and governments.
This blog post will first provide an in-depth review of the problems the world’s internet architecture is facing, and then highlight the cjdns technology and how it represents a much needed optimization to the current internet.
The current internet protocol suite uses a conceptual model called the Open Systems Interconnection Model (OSI Model). The OSI Model is composed of seven layers: physical layer, data link layer, network layer, transport layer, session layer, presentation layer, and application layer, each of which serves different functions in networking.
Some of these technologies are familiar; for instance, the application layer is made up in part by protocols like Hypertext Transfer Protocol (HTTP), which is associated primarily with the World Wide Web, and Simple Mail Transfer Protocol (SMTP), which is used to send email. One specific protocol that makes up the network layer is the Internet Protocol (IP), from which the term “IP address” originates.
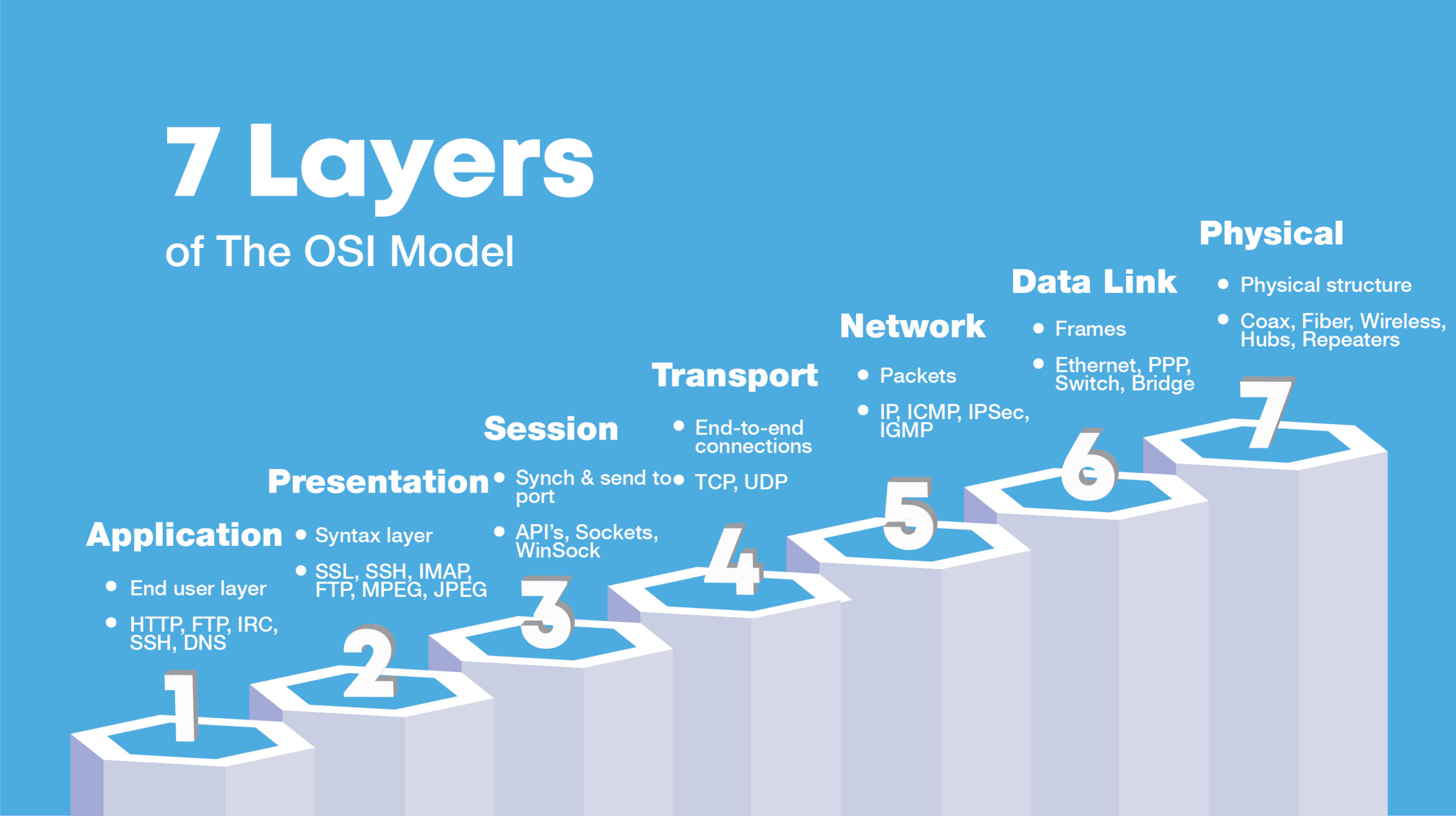
The OSI model was designed to standardize the communication functions of computer systems, without regard to the inner workings of those systems. While on the whole, this system still works, the constant development of newer technology using the same protocols, and the increase in users and devices with internet connectivity, has led to continuous scalability problems, not the least of which are the countless breaches and privacy erosion that is commonplace today.
Inefficient Routing Tables – A major current problem is the growth and scale of routing tables. A routing table is a list of rules, displayed in table format, that tells a data packet traveling over the internet where to go and how to get there. All IP-enabled devices (i.e., devices with an internet connection, such as smartphones), use routing tables.
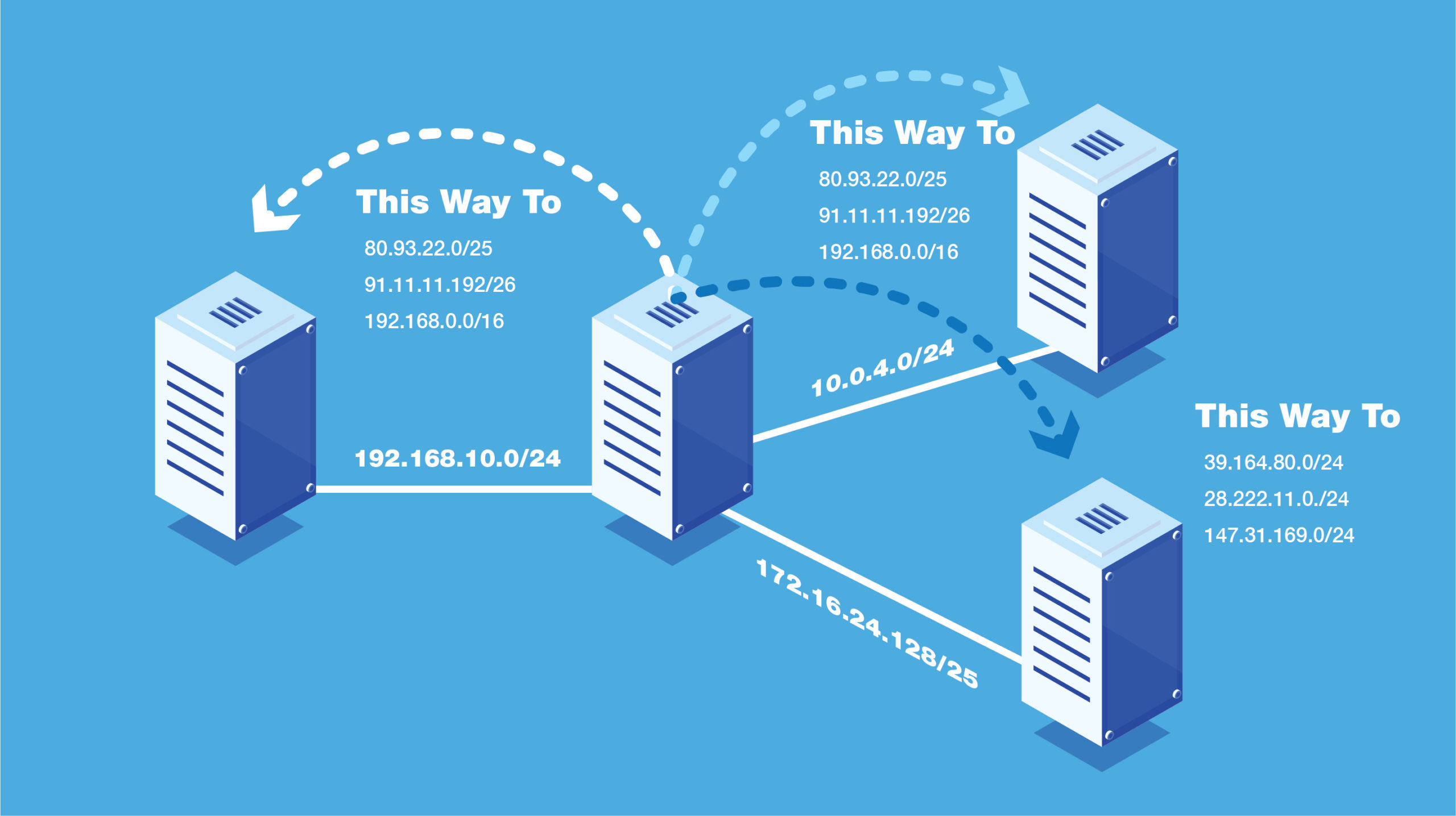
Metaphorically, these routing tables are the equivalent to maps and roadway traffic signs, and the data packets moving across the internet are like cars. Just like traffic signs provide transit information to cars, the routing tables give instructions as to where these “cars” should travel.
If IP addresses are in large blocks, a router can look at the first numbers in the address (like the blue signs in the above diagram) and tell where a data packet is destined for. However, the router will not know exactly which wire to send it through.
To handle the ever-increasing size of routing tables, the networking company Cisco has proposed a new protocol called Locator/Identifier Separation Protocol (LISP). The basic concept of LISP is to separate the addresses used by people’s devices (such as smartphones) from those used by routers.
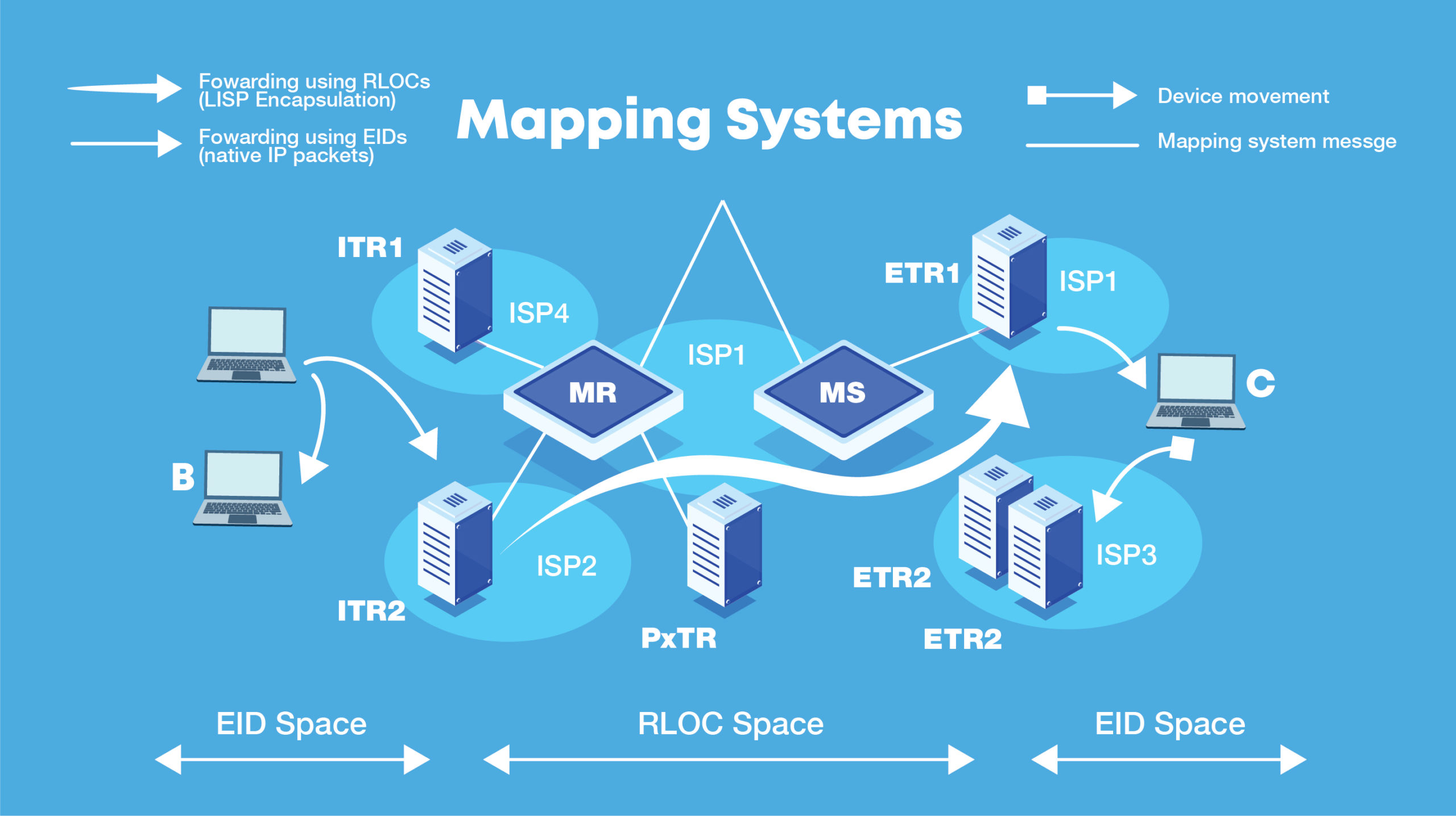
The LISP protocol separates these addresses into two categories called Endpoint Identifiers (EIDs), which are assigned to end hosts, and Routing Locators (RLOCs), which are assigned to devices (mostly routers), that comprise the global routing system.
The LISP system has the advantage of allowing edge ISPs and users to view the internet as they see fit, broken into sections for political or convenience reasons, while routers view the internet as a top-down series of addresses, connected at an origin point. While LISP works well on current routers, it is limited in its scope, whereby if it requires looking up the real location of a server to send a packet, it should figure out the fastest path as well, but it doesn’t. LISP helps scale the network, but the underlying prefix-matching technology is still in use, and thus it is not as efficient as source routing can be.
Data Breaches – A data breach, “…is an unauthorized access and retrieval of sensitive information by an individual, group, or software system. It is a cybersecurity mishap which happens when data, intentionally or unintentionally, falls into the wrong hands without the knowledge of the user or owner.” Data Breaches have been consistently mentioned in the news, with notable, major breaches such as the 2006 AOL data search scandal, the 2011 PlayStation user account leak, and the Equifax breach in 2017, to name a few. One reason for such incidents is the lack of security in internet protocols like HTTP, which many websites still use.

Some organizations, such as the Electronic Frontier Foundation and the Tor Project, have worked to address this issue through plugins like HTTPS Everywhere, which forces many websites to default to HTTPS. Unfortunately, many major social networks, like Facebook and Twitter, continue to suffer from data breaches for other reasons, such as sensitive information being exposed via cloud services and backdoor attacks.
Another common problem with the present-day internet is distributed denial-of-service (DDoS) attacks. These attacks occur when an attacker knocks a service offline by flooding a network with more data packets than it can handle. With the growth of the Internet of Things (IoT), it has made it easier and more commonplace for such attacks to occur.
IoT consists of many different devices which are network-enabled, such as smartphones, routers, fitness trackers, smart appliances and smart home devices. While these devices offer increased convenience, they also create security vulnerabilities. When a large number of IoT devices are compromised, it becomes easy for attackers to perform even more devastating DDoS attacks. For example, in 2021, a massive DDoS attack took down the websites of more than 200 organizations across Belgium, and in 2016, the company Dyn. Inc., which manages traffic for such high-profile sites as Twitter, Spotify, and Netflix, was hit by one such attack, knocking all of these major services offline for hours.
Despite the regularity of such attacks, it is rarely an emergency for the owner of an infected device, nor even an ISP, until one of their networks becomes the target. Sometimes DDoS attacks are political in nature, whereby the attack is used to intimidate someone who may be hosting controversial content. Often, data centers respond by taking down flagged content, which makes DDoS a powerful censorship tool.
A second form of DDoS is the threat of faux court action to an ISP, which is far more deceptive. Because the ISP, in most cases, provides IP addresses to customers, it becomes the ISP’s responsibility as to whether to disconnect a customer in order to avoid the legal consequences. The implicit danger is when giving the ISP the choice of self-preservation or censorship. This equates to an asymmetrical power, often against a victim who may have had no control over the situation.
Cjdns aims to address and correct many of these internet protocol suite weaknesses which are, in part, responsible for these DDoS attacks, data breaches, and other problems.
A data packet’s journey begins at a user interface device, such as a TUN device. The user sends an IPv6 packet, which enters the TUN device and then enters the cjdns engine. The packet is then checked for authenticity (i.e. whether its source and destination addresses are accurate); a router lookup is also performed on the destination address.
Cjdns addresses consist of the first 16 bytes of the SHA-512 of the SHA-512 of the public key (known as a double SHA-512). All of these addresses must begin with a byte called 0xFC. If they do not begin with this byte, they are considered invalid, so brute force is used to keep generating keys until the result begins with 0xFC.
Following the router lookup, the node will check that it has a CryptoAuth session with the destination node, if it does then it will encrypt the packet using this session, otherwise it will hold it in memory while setting one up. While the encryption process does add data to the packet, making it less efficient use of bandwidth, the IPv6 source and destination addresses are removed as the destination is aware of this information from the CryptoAuth session itself.
After this process takes place, the packet is ready to be sent to the selected router. When sending the packet, a CryptoAuth session is chosen for the router’s address, and the packet is passed through it for routing.
The switch takes the packet and passes it to a network module. The module uses another CryptoAuth session to encipher and authenticate the packet from the switch header all the way to the end. The data which comes from this process is put together in a network node and then sent to the next switch for routing.
After it receives the packet, the next node sends it through its CryptoAuth session, which reveals the switch header, and then sends the packet to its switch. In most cases, the switch will then send the packet to a different endpoint according to what the packet label says. In some cases, however, the switch may send the packet to its router, and the packet will reach its determined destination.
Cjdns replaces the standard “where do you want to go” routing scheme with that of “how do you want to get there.” This is what cjdns refers to as Compact Source Routing. Its components are dependent on both of the others: the router is unable to work without routing in a small environment created by the switch; the switch has no sense of direction without the router to direct it; and the CryptoAuth has nothing to protect without the router and switch.
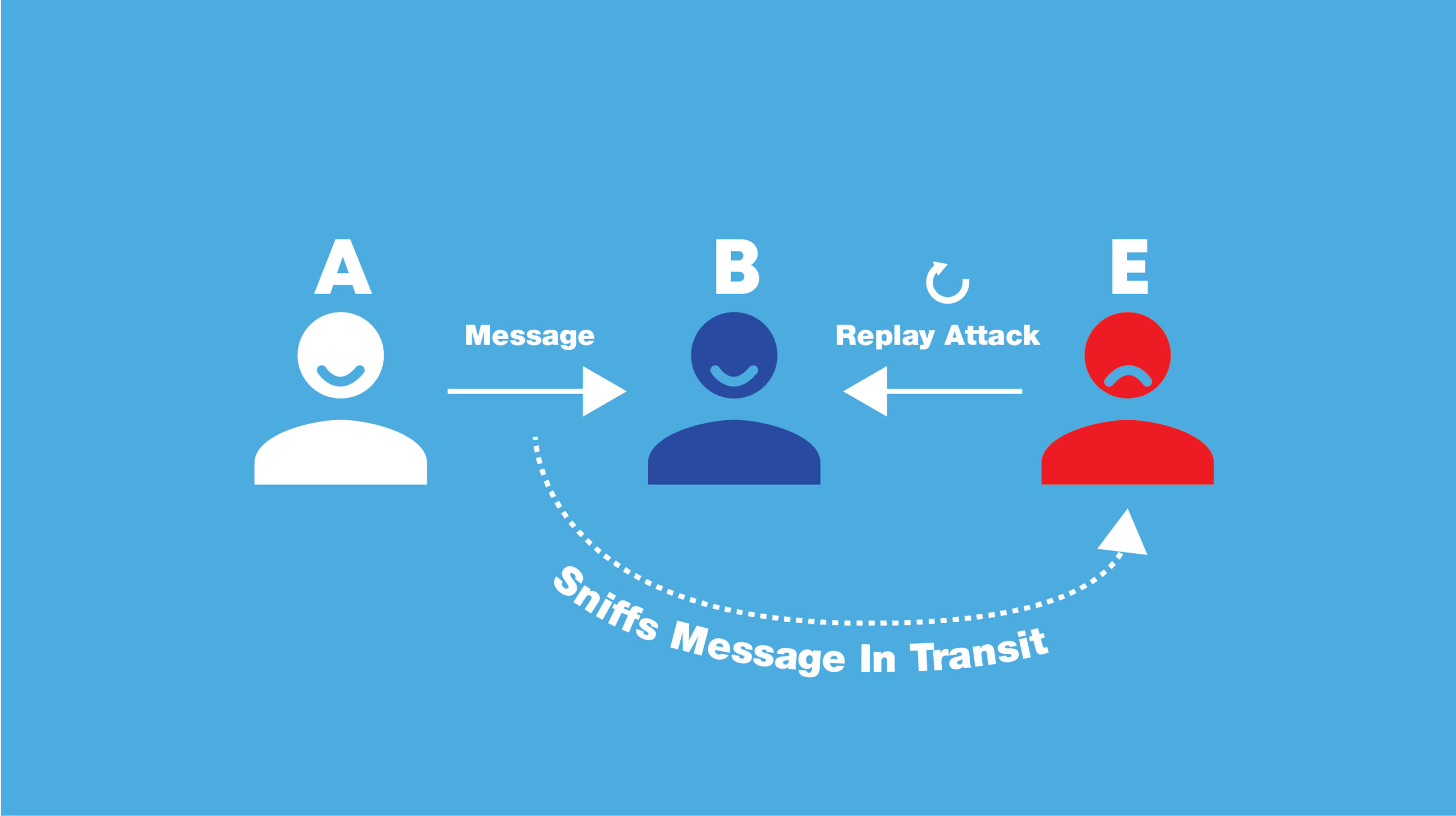
CryptoAuth is a system for wrapping interfaces. You enter an interface (which may or may not include a key), and it replies with a new interface which allows you to send packets to someone who has that key. Like other parts of cjdns, it is intended to work with best effort data transit. CryptoAuth’s handshake is based on piggybacking headers on regular data packets; the traffic in handshake packets is encrypted and authenticated, but is not invulnerable to replay attacks, and also lacks forward secrecy if an attacker gets possession of the private key.
Three types of CryptoAuth headers exist:
All CryptoAuth headers are 120 bytes long, with the exception of the Data Packet header, which is only 20 bytes. The first four bytes of any CryptoAuth header is a big endian number which is used to determine its type; this is known as the “Session State” number. If it is one or two, it is a Hello Packet or a repeated Hello Packet; if it is three or four, it is a Key Packet or a repeated Key Packet. If it is larger than four, it is a Data Packet. Note: the term “nonce,” as used here, refers to a number used to protect private communications by preventing replay attacks (illustrated below).
The handshake packet structure looks like the following (Hello, Key):
1 2 3
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
0 | Session State |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
4 | |
+ +
8 | Auth Challenge |
+ +
12 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
16 | |
+ +
20 | |
+ +
24 | |
+ Random Nonce +
28 | |
+ +
32 | |
+ +
36 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
40 | |
+ +
44 | |
+ +
48 | |
+ +
52 | |
+ Permanent Public Key +
56 | |
+ +
60 | |
+ +
64 | |
+ +
68 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
72 | |
+ +
76 | |
+ Poly1305 Authenticator +
80 | |
+ +
84 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
88 | |
+ +
92 | |
+ +
96 | |
+ +
100 | |
+ Encrypted/Authenticated Temporary Public Key +
104 | |
+ +
108 | |
+ +
112 | |
+ +
116 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ Variable Length Encrypted/Authenticated Content +
| |
The data packet structure looks like this:
1 2 3
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
0 | Nonce |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
4 | |
+ +
8 | Poly 1305 Authenticator |
+ +
12 | |
+ +
16 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
20 | |
+ Variable Length Data +
24 | |
Hello Packet – If the “Session State” field equals zero or one, then the packet is a Hello Packet or a repeated Hello Packet. If no connection exists, then one may be created and the recipient may send a Key Packet back but it is recommended that he wait until he has actual data to send. On the other hand, a node who has sent a Hello Packet, gotten no response, and wishes to send more data MUST send that data as more (repeat) Hello Packets. The temporary public key and content are both encrypted and authenticated using a function called crypto_box_curve25519poly1305xsalsa20_afternm(), using the shared secret computed as described in the Authentication field’s section.
Key Packet – If the “Session State” field equals two or three, then the packet is a Key Packet. Key Packets are replies to Hello Packets. As Hello Packets do, they contain a temporary public key, which is encrypted and authenticated in combination with the other data. After receiving a Key Packet, a node may start sending Data Packets. The content and temporary key is encrypted and authenticated using a function called crypto_box_curve25519poly1305xsalsa20_afternm(), which uses the shared secret, computed using the function crypto_box_curve25519poly1305xsalsa20_beforenm(). These refer to a combination of different types of cryptographic authentication. The latter function uses one peer’s temporary public key and the other peer’s permanent secret key.
Data Packet – This is the default data packet and the first four bytes of which are used as the nonce (i.e. a random or non-repeating value included in a data exchange like this one). In this instance, it is a 24-byte nonce and the function crypto_box_curve25519poly1305xsalsa20_afternm() is used to encrypt and decrypt the data. This uses the shared secret computed using the function crypto_box_curve25519poly1305xsalsa20_beforenm(), and one peer’s temporary public key along with the other peer’s temporary secret key. The function crypto_box_curve25519poly1305xsalsa20_beforenm() requires a 24-byte nonce, so the 4-byte nonce is copied in a 24-byte array which is sent to the primitive. The peer who sent the Key Packet enters it into the first four bytes of the array; the other peer writes it in the next four bytes. This is done in order to prevent one peer from sending packets back to the other, and falsely claiming that these packets came from the former.
The design of the Switch differs from an IP or an Ethernet router, inasmuch as it does not need to have knowledge of the globally unique endpoints in the network. As with Asynchronous Transfer Mode (ATM) switching, the packet header is altered at each hop along the path, and the reverse path can also be obtained at the end point or at any hop on the path. Unlike ATM, however, with cjdns the switch does not store active connections, nor is there any connection setup.
When a data packet reaches the switch, the switch reads the least significant information on the Route Label in order to establish the Director, and therefore the Interface, in order to send the packet on its way. The Route Label is then shifted to the right according to the number of bits in the Director, which essentially removes the first Director and then exposes the Director that belongs to the next switch in the path. Prior to sending the packet, the switch uses its Encoding Scheme to create a Director that symbolizes the interface from which the packet came. Then it does a bitwise reversal and puts it in the empty spot to the left of the Route Label, which the previous bit shift exposed.
For example, if Alice wants to send a packet to Fred through Bob, Charlie, Dave, and Elinor, she would first send a message to her switch, with the first Director telling her switch to send its interface to Bob, the second Director telling Bob’s switch to send it to Charlie, etc.
Alice’s original Route Label, before entering her switch, is as follows:

Route Label when it reaches Bob:

Route Label when it reaches Charlie:

Route Label when it reaches Dave:

If Dave cannot forward the packet and needs to send an error message, he has no knowledge of where Charlie’s Director ends and Dave’s begins, so while he cannot reorder them, because they are bit reversed, he can reverse the order by bit reversing the whole Route Label.

There are still several functions which can be performed through a Route Label, in spite of its opaque quality: Splice, Unsplice, and RoutesThrough. As explained in more detail below, Splice concatenates Route Labels together, while Unsplice splits them apart.
The Splice operation takes a Route Label from point A to point B and concatenates it (i.e. joins it together) with a Label from point B to point C, yielding a Route Label for a route from point A to point C.
Splicing is performed by Exclusive or-ing (XORing) the second part with 1 and shifting it to the left by the log base 2 of the first part, then XORing the result with the first part.
Given:
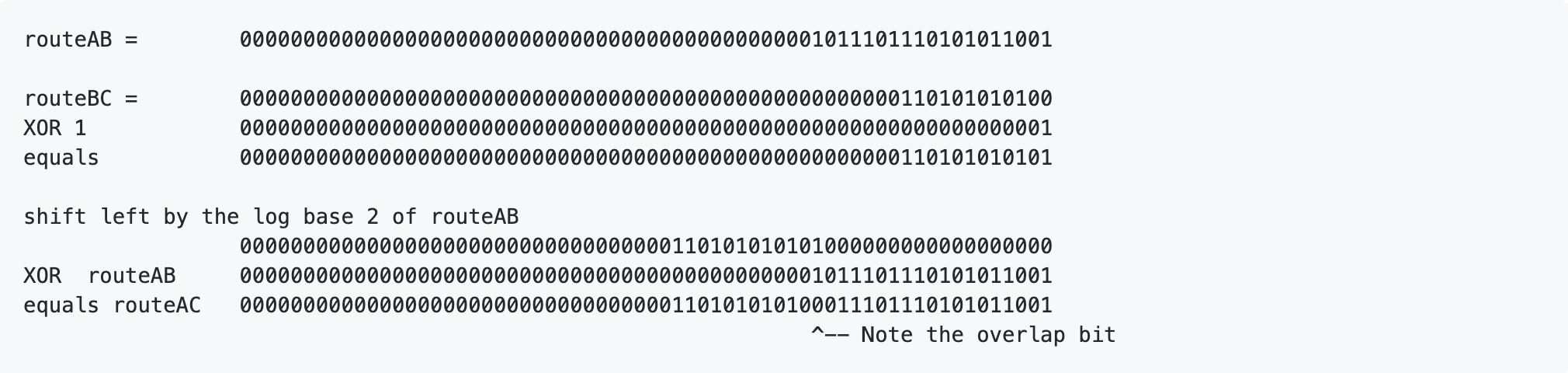
The log base 2 serves as the index of the first set bit, starting from the right. In other words, shifting by the log base 2 leaves 1 bit of overlap remaining; this combined with the XORing of the second part (routeBC) against 1 causes the highest bit in the first part to be overwritten.
Unsplice is the inverse of the splice operation; it converts a full Route Label to a representation which would be helpful to a node along the path. In other words, it derives routeBC from routeAC and routeAB.

Given the option of two routes, there is the possibility of determining whether one route is the extension of another. This is quite a bit like the opposite of the splicing routine. To figure out whether or not routeAC “routes through” the node at the conclusion of routeAB, one would remove the most significant 1 in routeAB, and trim the left side of routeAC so that they are both the same length, and compare the results of the two.

If routeAC routes through the node at the end of routeAB, then they are equal.
Cjdns implementations offer a feature called ReplayProtector, though it is not part of the protocol itself.
A simple form of the replay protector drops any data packet whose nonce is lower than or equal to the highest nonce received thus far. This is done so that a packet can never be sent twice to a node, in order to prevent replay attacks.
The “official” cjdns implementation uses a replay protector to prevent such attacks; however, it’s not necessary to use this just for supporting the protocol.
Each time a node receives a packet, it contrasts its nonce with the highest nonce that has been received thus far, which is a big-endian integer. If the nonce is greater, this indicates there are no problems; the packet is not a replay attack. There is also the possibility that the packet is a late packet, i.e. a newer packet has already been received.
The slotted replay protector allows late packets to be received by using a 64-bit bitfield, with one bit representing each of the 64 nonces before the highest one. Each time a packet is received with a nonce between highestnonce – 64 (excluded) and highestnonce (included), it subtracts the packet’s nonce from the highest nonce. The result is a number, n, which represents the nth bit of the bitfield. If the number is one, then the packet is a replay, and it will be dropped. If the number is zero, then the packet passes, and the bit will be set to one.
The authentication field allows a cjdns node to connect using a password or some other shared secret; the AuthType field tells the node how to connect using the secret aspect, as in the following diagram:

The field “AuthType Specific” refers to the type of authentication being used (i.e. a password or cryptographic key).
AuthType Zero means that no authentication is being used. In the case where AuthType is set to zero, any AuthType Specific fields are ignored; they are set to random numbers in this case. AuthType Zero is used in Key packets and inner (end-to-end) CryptoAuth sessions.

AuthType One is an authentication method that is based on the Secure Hash Algorithm-256 (SHA-256). In AuthType One, the password is hashed once, and applied to the output of the multiplication of the previously mentioned curve25519 keys. It is then hashed again, with the result being copied over the first 8 bytes of the authentication header, before setting the AuthType field. The “hash code” field contains bytes 2 through 8 of the hash of the password. This authentication is used in a similar manner to a username, so that the person on the opposite end knows which password to enter in the handshake.
AuthTypeTwo, while similar to the first, uses bytes 2 through 8 of the SHA-256 hash of a login. The receiver of the packet knows that these bytes represent the password which is used to make the symmetric secret.
To further understand the workings of cjdns, it may be helpful to first define terms related to it. They are as follows:
Cjdns is working to solve many of the problems that face the current design of the internet. Its components work in tandem to make a more secure, modern, and fast network, and have protections against common attacks such as replay attacks, data breaches and DDoS attacks, which plague websites almost daily. As it is developed further, and hopefully adopted by more users, it can serve as a building block for a future vision of what the internet could be.
Go back to Blog →Share this article with your friends

Updates
The PKT Town Hall Newsletter – Issue #7 On May 25th, 2023 the PKT Cash community hosted a town hall event to discuss the current updates in the ecosystem. Speakers…

Updates
As August 2021 wraps up, the PKT community is growing at a remarkable rate. There are many notable milestones and achievements to share. PKT is an open-source project. All of…